반응형
여기서 말하는 Resource는 "CRD(Custom Resource Definition)"의 Resource가 아니라, 정말 "자원"개념의 "Resource"다.
GPU는 왜 나눠쓸 수 없을까?
- 나는 NVIDIA RTX 8000 GPU를 Node에 1개 달아둔 환경에서 작업중이다.
- NVIDIA RTX 8000은 Datacenter에서 사용할 수 있도록 허용된 NVIDIA 드라이버 라이선스가 있으며, 무려 VRAM이 48GB 나 된다!!!

- Kubernetes에는 리소스 쿼터라는 개념이 있어서, CPU, RAM을 나눠서 사용할 수 있도록 기능을 제공해 준다.
- 관련링크 : kubernetes.io/docs/concepts/configuration/manage-resources-containers/

- 예를들어, Pod를 띄울때 아래와 같은 설정을 추가하면
- Pod가 최소한 0.25vCPU 와 64MByte 메모리를 사용할 수 있도록 확보-선점(requests)한 상태에서 뜨게 되고,
- Pod가 최대한 0.5vCPU와 128MByte 메모리까지(limit)만 사용할 수 있게 된다.
- 관련링크 : kubernetes.io/docs/concepts/configuration/manage-resources-containers/

- Pod에서 GPU를 사용하려고 할 때도, 위와 비슷한 방법을 제공한다.
- NVIDIA GPU Device Plugin을 설치하면, 아래의 방법으로 GPU를 할당 받아서 사용할 수 있다.
- 관련링크 1 : https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
- 관련링크 2 : https://github.com/NVIDIA/k8s-device-plugin
- 아래와 같이
spec/containers/resources/limits/nvidia.com/gpu : 1와 같이 값을 주면, 해당 컨테이너에서 GPU를 1개 사용하겠다는 뜻이다.
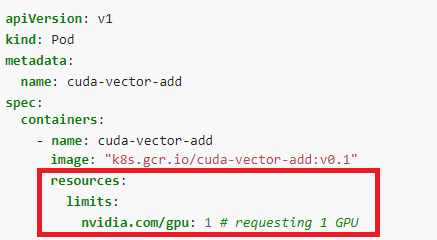
- 하지만, 이 방법은 나에게는 치명적인 문제가 있다. 위와 같이 사용하면 해당 컨테이너가 1개의 GPU를 "온전히 선점해서" 사용하도록 설정되므로, 다른 컨테이너 설정에 resource limits를 또 적어 준다면, 뒤에 띄울 컨테이너를 GPU를 할당 받지 못해 컨테이너가 뜨지 않는 문제가 있다.
- 아, CPU와 RAM 처럼 Request와 Limit 같은걸로 최소는 0개, 최대는 1개로 설정하면 안되겠냐고? 안된다. 왜나면 안된다고 적혀 있기 때문에...
- 또한, GPU 1개를 여러개로 쪼개서 쓸 수 없냐고? 없다. 왜냐면 안된다고 적혀 있기 때문에...

- 즉, Kubernetes에서 현재 지원하는 GPU 할당 개념은, GPU 개수 단위로만 할당이 가능하다.
- 만약 내가 띄워야 할 Container에서 GPU를 겨우 VRAM 4GB를 사용하는데, 48GB 가 달린 GPU 1개를 전체로 할당해 버리면, 나머지 44GB는 어떻게 활용하지?
- 결론적으로 이야기하면 내 환경에서는
nvidia.com/gpuresource 제약을 사용하면 바보다. ㅎ.
그럼 nvidia.com/gpu 를 옵션을 아예 빼고 사용하면 안될까?
- 당연히 안된다.
- 예를들어 내가 운영중인 Node의 하드웨어 스펙이 아래와 같다고 하자.
- vCPU : 10 core
- RAM : 32 GByte
- VRAM : 48 GByte
- 그리고 내가 띄우려고 하는 Container의 스펙은 아래와 같다고 하자. ( request 만 계산 )
- vCPU : 1 core
- RAM : 2 GByte
- VRAM : 12GB
- 이 상황에서 Container를 5개 띄운다고 계산해 보자.
- 컨테이너 1개당 vCPU는 1 core를 사용하니까, 5개를 띄워도 5core를 사용하니 cpu는 문제 없음
- 컨테이너 1개당 RAM은 2GB를 사용하니까, 5개를 띄워도 10GB 를 사용하니 RAM은 문제 없음.
- 컨테이너 1개당 VRAM은 12GB를 사용하니까, 5개를 띄우면 60GB를 사용해 실제 VRAM 사용 가능량 보다 초과 됨.
- Resource에 대한 request 제약은 cpu와 RAM만 줄 수 있는 상황이다.
- VRAM의 제약에 대해서 kubernetes는 알지 못하므로, 5번째 container가 뜰때, process에서 VRAM을 사용할 것이다. 그런데 실제 하드웨어에서는 VRAM이 부족해서 process가 뜨다가 죽을 것이다.
- Kubernetes는 "상태유지"를 위해서 죽은 애를 살릴 것이다. 그러므로 kubernetes는 계속 5번째 container를 띄우려고 하고, 계속 죽을 것이다.
- Resource가 부족해서 Pending 되면 문제 발견이라도 쉬울텐데, 이건 걍 살리려다 죽고, 다시 살리고, 다시 죽고...
Extended Resource 를 활용해, 편법으로 회피하자
- Kubernetes에서는 "나만의 Resource"를 정의해서 사용할 수 있게 만들어 두었다.
- 여기서 말하는 Resource는
CRD(Custom Resource Definition)이 아니라, 정말자원개념의Resource다. - 관련링크 : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#extended-resources

- 쉽게 말하면,
node별로 값(capacity)을 정해놓고, 이 값을 Cotainer에 할당할 수 있다. 만약 Container에서 필요로 한 양보다 남아 있는 값이 작으면, Deploy 상태가 Pending 되어, 문제 상황을 확인할 수 있다. - Container에서 사용하는 VRAM의 값을 잘 알고 있다면, VRAM에 대한 Extended Resource를 등록하고, Container에서 VRAM 값을 깍아 가면서 사용하면 될 것이다.
- 참고로, 위에서 NVIDIA GPU에 대한 제약을 정할때
Device Plugin이라는것을 설치했는데, 거기서도Extended Resource가 정의되어 사용된 것이다.
테스트 환경
- 테스트하는 환경은 아래와 같다.
- k3s-m1 : k3s로 master(cluster-init) 설치, 1vCPU, RAM 2GB
- k3s-w1 : k3s로 worker(agent) 설치, 1vCPU, RAM 2GB, VRAM은 4GB 있다는 가정.
- k3s-w2 : k3s로 worker(agent) 설치, 1vCPU, RAM 2GB, VRAM은 8GB 있다는 가정.
현재 Resource 확인하기
- kubernetes API Server에 http
PATCH를 보내서 값을 업데이트 해 주면 된다. - 우선, 지금 node에 설정되어 있는 Resource 목록들을 먼저 살펴 보자.
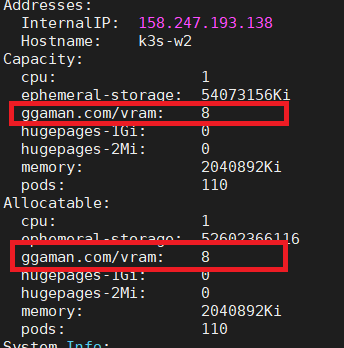
kubectl describe node k3s-w2명령을 사용하면k3s-w2node에 설정된 Resource 목록을 볼 수 있다. ( 출력의 위 아래는 생략했다. )

k3s-w2node에는cpu,memory,pods등의 값을 Resource로 가지고 있다.
Extended Resource를 node에 추가 하기
- 우선 API Server에 HTTP call을 편리하게 하기 위해서 proxy를 열어 주자. master 서버에서 하면 편할것이다. 명령어는
kubectl proxy이다.

kubectl proxy명령을 치고 나면,127.0.0.1:8001로 port가 열리게 된다.- 이제, 나만의
vram Resource를 등록하자. proxy를 위해서 위 명령창은 떠 있는 상태로 둬야 하므로 새로운 터미널 창을 열어 아래의 명령을 입력하자.
curl --header "Content-Type: application/json-patch+json" --request PATCH --data '[{"op": "add", "path": "/status/capacity/ggaman.com~1vram", "value": "8"}]' http://localhost:8001/api/v1/nodes/k3s-w2/status- 위 명령은
k3s-w2node에ggaman.com/vram이라는 Resource를8로 등록한 것이다. 이 명령을 치고 나면 결과가 주루룩 출력된다. 그 결과를 봐도 좋겠지만, 우리는 node의 정보를 다시 확인하면서 vram 관련 항목이 추가 되었는지 확인해 보자.kubectl describe node k3s-w2명령을 치면 아래과 같은 내용을 확인해 볼 수 있다.
- 아, 왜 이름을
ggaman.com/vram으로 했냐면, 그렇게 하라고 하니깐 그런거다.

- 좀 더 정확히
curl명령을 정리하면 아래와 같다.
curl --header "Content-Type: application/json-patch+json" --request PATCH --data '[{"op": "add", "path": "/status/capacity/[내가정의하고자하는ExtendedResource이름]", "value": "[리소스개수]"}]' http://localhost:8001/api/v1/nodes/[새Resource를등록할node이름]/status- 만약 Extended Resource를 지우고 싶다면, 위 json에서
add를remove로 변경해 주면 된다.
Extended Resource 사용하기
- 사용하는건 간단하다. 기존 Pod 생성할 때 Resource 설정하는것 처럼 하면 된다. vram을 3개씩 사용하는 Pod를 여러개 띄워 보자.
- 관련링크 : https://kubernetes.io/docs/tasks/configure-pod-container/extended-resource/
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo-1
spec:
containers:
- name: extended-resource-demo-ctr-1
image: nginx
resources:
requests:
ggaman.com/vram: 3
limits:
ggaman.com/vram: 3- 위 Pod의 이름을 1~4까지 값을 주면서 띄워 보자.
- Extened Resource는 아래와 같이 등록해 두었다. 위에 알려준 명령으로 등록하면 된다.
- k3s-w1 - ggaman.com/vram capacity : 4
- k3s-w2 - ggaman.com/vram capacity : 8
- 이 상황이면,
k3s-w1에 1개의 Pod가,k3s-w2에 2개의 Pod가 배치되며, 4번째 Pod는 Pending 되어야 할 것이다. - 순차적으로 수행해 보자.

- 처음으로 배포된 Pod는
k3s-w1배포 되었다는것을 알 수 있다. 이제k3s-w1node 정보를 확인해 보자.kubectl describe node k3s-w1명령을 통해 확인 할 수 있다.
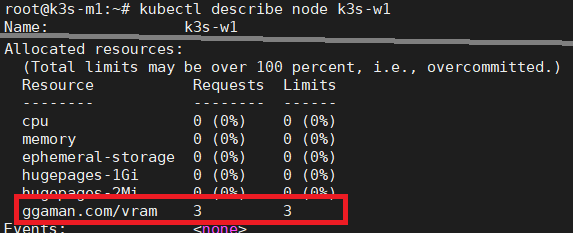
- 보다시피
k3s-w1에Allocated resources에ggaman.com/vram이 할당 된 것을 볼 수 있다. - 이제 두번째 Pod를 배포해 보자.

- 보다시피 두번째 Pod는
k3s-w2에 배포 되었다. 우리가 설정한ggaman.com/vramResource를 잘 사용했는지 확인해 보자.

- 뭐 볼거 없이 잘 사용 되었다. 이제 세번째 Pod를 배포해 보자. 지금 예상대로라면,
k3s-w1에는ggaman.com/vram이1이 남아 있고,k3s-w2에는5가 남았을 것이므로,k3s-w2에 배포되어야 한다. 자, 이제 세번째 Pod를 배포하고 결과를 보자.

- 예상한대로 동작했다. 세번째 Pod는
k3s-w2에 배포 되었고, 우리가 정의한ggaman.com/vramResource 도 3개가 더 사용되어 현재 사용중인 Resource는 총 6개가 되었다. - 이제
k3s-w1에 남아 있는ggaman.com/vram의 Resource는 1개,k3s-w2에 남아 있는ggaman.com/vramResource는 2개이므로, 네번째 Pod를 배포하면,ggaman.com/vram의 Resource가 충분한 node가 없으므로, 어디에도 배포되지 못하고Pending되어야 할 것이다. 자, 시도해 보자.

- 예상한대로 네번째 Pod는 적절한 node를 찾지 못하고
Pending된 상태이다.Pending된 이유도 살펴 보자. 예상대로라면 "ggaman.com/vram에 대한 Resource가 부족해서 배포되지 못하고 있다." 정도의 메세지가 보이면 될 것이다.

- 모든것이 예상대로 동작했다.
정리
- Kuberntes에서는 아직 1개의 GPU를 여러개로 쪼개서 사용하는게 불가능하다.
- 그렇기 때문에, GPU의 VRAM을 나눠서 사용하고 싶다면 다른 방법을 찾아야 한다.
- 만약, Container에서 사용하는 GPU의 사용량을 정확하게 안다면,
Extended Resource를 사용하면 편법으로 나눠서 사용할 수 있다. Extended Resource를 설정하는것은 Kubernetes API Server로 PATCH request를 던지를 방법으로 추가 할 수 있다.- Pod를 생성할때 우리가 지정한 자원을
resources의requests,limits에 적절히 설정하면 배포가 가능한 node에 가서 알아서 배포가 된다. - 만약 우리가 지정한 자원의 양이 부족해서, 배포가 될 node가 없다면
Pending걸리게 된다.
참고
- 만약 Container에서 동작중인 엔진이 우리가
ggaman.com/vram에 정의한 양보다 더 많은 VRAM을 사용한다고 해도 막을 수 있는 방법은 없다. - 그러므로
ggaman.com/vram의 값을 줄 때는 해당 엔진이 최대로 사용할 수 있는 VRAM의 양을 측정한 뒤에 사용해야 한다. - Sidecar container에서 main container에서 돌아가는 엔진의 VRAM 사용량을 주기적으로 체크해, 과도하게 커지면 죽이는 방법도 있을듯 하다. (
shareProcessNamespace: true사용 ) 하지만, 그런 트릭은 쓰지 말고 처음부터 잘 측정하자.(고 말하기에는 이것도 트릭인데.. ㅎㅎ ) - Kubernetes에서 1개의 GPU를 여러개로 쪼개쓰는것은 안되지만, GPU자체를 Virtualize 해서 여러 VM에 할당하고, 각 VM을 Kubernetes node로 연결하는 방법(vComputeServer)은 있는듯 하다. 하지만, VMWare 같은 프로그램이 필요하고, DataCenter에서 사용가능한 비싼 GPU 모델에서만 동작한다. 심지어 유료다. T_T 다음에 기회가 되면 관련 글을 써 보도록. ㅎ.
반응형
'공부 > 컴퓨터' 카테고리의 다른 글
| [PyTorch] 1.8 release와 함께 GPU memory fraction 이 지원됩니다. - torch.cuda.set_per_process_memory_fraction (0) | 2021.03.14 |
|---|---|
| [Vultr] VPS Instance Type 별 CPU 속도 확인 (0) | 2021.03.01 |
| [Kubernetes] k3s 1.20이하에서 Traefik 1.81 제거하고 Traefik 2.x 설치하기 (0) | 2021.02.26 |
| [python] Flask로 app.run() 실행시 두개의 Process가 뜨는 문제 (1) | 2021.02.25 |
| [Kubernetes] k3s에서 컨테이너를 띄웠는데 왜 GPU를 못 쓰지? (0) | 2021.02.22 |



