반응형
책 읽은것 정리, 그리고 Cheat Sheet 용으로 ChatGPT랑 공부를 좀 했음
제목 : Tucker의 Go 언어 프로그래밍 - 공봉식, 골든래빗

책을 읽기전
- Go라는 언어가 예전부터 나왔지만, 잠시 공부했다가 그냥 그런가 보다 했다.
- 한창 Docker와 Kubernetes를 관련 업무를 진행할 때 이 쪽 관련 주 언어는 Go 인걸을 알게 되었다. 그래서 관심을 가지고 있다 읽게 된 책이다.
- 나의 주 언어가 Java이긴 하지만, Spring이 좋고 말고를 떠나서 다른 언어들에 비해서 메모리도 많이 사용하고, 메모리 관리가 어렵다는게 큰 문제 라는것을 최근에 격고 있다.메모리 관리는 GC 가 알아서 해 주니 뭐가 문제냐고 생각할 수도 있지만, 내가 말하는 메모리 관리 문제는 Memory Leak 이나 혹은 Stack Overflow 따위의 문제를 말하는게 아니다.
- 자바는 기본적으로 VM에서 Heap 이라는곳에 이런 저런 정보들을 두기도 하는데, 문제는 단순히 stack이나 heap이라는 메모리만 사용하는게 아니라 "native" 메모리도 사용한다는거다.
- 요즘에는 Container로 서비스를 올릴때, "이 컨테이너는 요만큼의 메모리만 사용해라"라고 지정해서 올리는데, Container OutOfMemory로 컨테이너가 죽는 경우가 있다. JVM이 Heap은 조금만 사용하는데 Native 메모리를 많이 사용하면서, 결과적으로 Container의 메모리가 부족해지는 경우가 있다.
- Heap 메모리가 부족해서 서비스가 죽으면, Heap dump라도 떠서 디버깅이라도 할 수 있는데, Native 메모리가 부족한 경우 추적하기가 너무 어렵다. Native단을 분석하는 시간보다 "Container 메모리 늘리기"라는 편한 방법을 취하게 된다는게 참 마음에 안 들었다.
- 이런 상황을 몇번 겪다보니 다른 언어에 눈이 가는것은 당연하긴 하다. 암튼 지금 내 생각이 그렇다고. ㅎ.
책 읽기
- 이 책을 쓰신분이 Go 언어의 A-Z까지를 다루기 위해서 노력한 흔적이 보인다.
- 이 책은 프로그래밍 자체를 모르는 초보자를 위한 책이라고 볼 수도 있다. 첫장의 제목이 "컴퓨터의 원리"라는것만 봐도 알 수 있다. 1장과 2장은 비트, 트랜지스터, 논리회로, op-code와 operand 에 대한 설명도 나온다. "이라고 볼 수 있다"라고 한 이유는, 1장과 2장이 "너무 전공자스럽다"는것이다. 4장도 다른 프로그래밍 언어 책에서는 그냥 넘어 갈만한 "부호비트" 따위에 대한 설명이 나온다. 제 글을 보고 이책을 보시는 분이 있다면, "굳이 다 이해할 필요는 없다. 조금 더 똑똑해지고 난 이후에 이해해도 될 것이다"
- 5장과 6장은 간단한 화면, 키보드 입출력을 다루고 있으며, 6장은 연산자를 다루고 있다.
- 7장부터 함수, 상수, if, switch, for, 배열, 구조체 포인터, 문자열, 패키지로 기본기를 끝내고
- 18장부터 슬라이스, 메소드, 인터페이스 함수 고급, 자료구조 , 에러핸들링, 고루틴, 채널, 컨텍스트가 나온다.
- 전공자급에서 배울법한 자료구조에 대한 설명도 나오고, 간단한 프로젝트들도 책에 포함되어 있으므로 책 한권을 모두 읽고 익힌다면 기본적인 프로그래밍은 할 수 있겠다 싶다.
책 정리는 이 정도 하고, 순전히 내가 나중에 참고하기 위해서 다른곳에서 구한 정보도 적절히 뒤죽박죽 정리한다. 위에도 적었다시피 Cheat Sheet 로 사용할 예정이니, 혹시 Go 언어에 대해서 이런 저런게 궁금하다면 이 문서에서 찾아 보면 되겠다.
기본정리
변수, 상수, 타입 변환 및 타입 체킹( type assertion )
////////////////////////////////////////////////////////////////////////
// 어떤 타입들이 있을까?
int, uint ( int와 uint는 32bit, 64bit 플랫폼에 따라 다른 정밀도를 가지게 되므로 되도록 절대 사용하지 말자 )
int8, int16, int32, int64
uint8, uint16, uint32, uint64
uintptr (포인터용)
float32, float64,
complex64, complex128 (복소수)
bool
string
rune ( Unicode CodePoint용, int32임 )
byte ( uint8 과 동일 )
////////////////////////////////////////////////////////////////////////
// 변수 선언
var b int64 = 10
// 타입을 적어도 되고, 안 적으면 알아서 추론 됨.
var e = 10
var f = 10.3
// := 를 사용하면 var이나 type을 적지 않아도 알아서 추론해서 값이 들어 간다.
// 근데 이때 걍 정수를 쓰면, int type으로 정의 된다. 그러므로 이렇게 쓰지 말자.
i := 10
// 물론 아래와 같이 쓰면 i는 int type, f는 float64로 들어감.
i, f := 10, 3.14 // 10, 3.14 - int, float64
// 근데 := 를 사용할 때는 적어도 하나의 변수는 이전에 사용하지 않은거여야 한다.
i := 10 // i는 처음 사용하는 변수라 := 를 사용 가능
i, f := 20, 5.9 // i는 이전에 사용했지만, f는 처음 사용한거라 := 라 가능
i, f := 30, 7.3 // error. i와 f는 모두 이전에 사용된거라 컴파일 에러.
////////////////////////////////////////////////////////////////////////
// 상수 선언
// const 상수이름 타입 = 값
const ConstValue int = 10
// ConstValue가 상수로 정의 되었으므로, 당연히 값을 할당하면 에러가 발생함.
// 상수는 "코드에 박히기 때문에", 메모리 주소를 출력할 수 없다.
// 그러므로 아래 코드는 에러가 발생함.
// fmt.Println(&C)
////////////////////////////////////////////////////////////////////////
// 타입변환, Go는 컴파일러가 암시적으로 타입변환 안해줌. 사용자가 명시적으로 해야함.
i := 42
f := float64(i)
u := uint(f)
// 호환되는 타입을 만든 경우, 상호 변환 가능.
type MyInt int
var i int = 42
var m MyInt = MyInt(i) // int -> MyInt
var q int = int(m) // MyInt -> int
////////////////////////////////////////////////////////////////////////
// string과 다른 type 간의 변환
// Atoi는 return type이 int 라서 시스템마다 다르게 반환 될 수 있다. 그러니 쓰지 말자!!!
i, err := strconv.Atoi("123") // 123 , int type이므로 system마다 다른 type이 될 수 있음!!
str, err := strconv.Itoa(123) // "123"
// string <-> primitive 타입 변환은 아래꺼 쓰자. 단 return type을 잘 확인해야 한다.
b, err := strconv.ParseBool(s string) // return (boolean, error)
// s를 base진법, bit만큼의 정밀도로 변환하고, 변환 결과를 int64로
i, err := strconv.ParseInt(s string, base int, bit int) // return (int64, error)
// s를 base진법, bit만큼의 정밀도로 변환하고, 변환 결과를 uint64로
i, err := strconv.ParseUint(s string, base int, bit int) // return (uint64, error)
// string float로
f, err := strconv.ParseFloat(s, 64) // return (float64, error)
// strconv.ParseFloat이 float64로 반환되었을때, float32로 변경하고 싶다면?
f64, _ := strconv.ParseFloat(s, 32) // ParseFloat가 float64를 반환하지만, 32bit 정밀로도 변환
f32 := float32(f64) // f64는 float64지만, 32bit 정밀도로 되어 있고, 이걸 다시 float32로 변환
////////////////////////////////////////////////////////////////////////
// 타입체킹 및 타입 단언(type assertion).
// interface{} 는 any type과 동일, 어떤 타입이던 우선 변수에 할당 받을 수 있음.
// variable.(TYPE)를 이용해서 타입을 알 수 있음.
// 만약 type이 맞다면 ok에 true가 i에 값이 들어옴.
// type이 맞지 않다면 ok에 false가 i는 초기값이 들어 있음.
var ivalue interface{} = 123
i, iok := ivalue.(int)
if iok {
fmt.Println("value contains an int:", i) // "value contains an int: 123"
} else {
fmt.Println("value does not contain an int")
}
var svalue interface{} = "hello"
s, sok := svalue.(string)
if sok {
fmt.Println("value contains a string:", s) // "value contains a string: hello"
} else {
fmt.Println("value does not contain a string")
}
////////////////////////////////////
// 인터페이스 타입이 아닌 경우 아래와 같이 타입 변환 불가
var f = 3.14
nf1 := f.(float64) // invalid operation: f (variable of type float64) is not an interface
// 아무타입이나 받을 수 있는 interface{} 를 이용해서, 받은뒤에 확인 가능.
var i interface{} = "hello"
f, ok := i.(float64) // i가 float64 타입이면, f에 값을. float64가 아니면 ok에 false를.
fmt.Println(f, ok)
////////////////////////////////////
// 인터페이스 타입을 변환할때도, 사용하기 전에 잘 변환되었는지를 잘 확인해야 한다.
// 그렇지 않으면 painc 발생. golang이 실수를 줄이기 위해 꼼꼼하게 설계 되었다는것을 알 수 있다.
nf := i.(float64) // panic. nf 값을 사용하려고 할 때, ok 값을 확인하지 않았으면 문제 됨.
fmt.Println(nf)
// 위 문장을 아래와 같이 ok부분을 _로 받아 두면 문제가 발생하지 않음.
nf2, _ := i.(float64) // 에러내용을 받았지만, "난 일부러 무시할꺼야" 라고 _ 로 받아 둔 것임.
fmt.Println(nf2)구조체, 타입 정의, 함수, 포인터 관련
package main
import "fmt"
// 함수명이 대문자이면 외부에서 호출가능한 public method라고 생각하면 됨.
// 리턴값이 1개
func Add ( a int , b int ) int {
return a + b
}
// 리턴값이 3개
func AddReturn3 ( a int , b int ) ( int, int, int ) {
return a, b, a + b
}
// 리턴값이 3개인데, 어떤게 리턴 될지 이름도 미리 정해 놔서 걍 "return" 이라고만 쓸 수 있음
func AddReturn3WithName ( a int , b int ) ( a int, b int, sr int ) {
sr := a + b
return
}
func main() {
// 타입이 명확할 때는 타입을 정의하지 않은 변수를 := 를 이용해 바로 만들 수 있음
c := Add(3, 5)
a1, b1, sr1 := AddReturn3WithName(3, 5)
}
////////////////////////////////////////////////////////////////
// 함수 가변 인자 및 ... 연산자
func Sum(nums ...int) int { // nums는 슬라이스로 전달됨
total := 0
for _, num := range nums {
total += num
}
return total
}
Sum(1, 2, 3)
nums := []int{1, 2, 3, 4, 5}
Sum(nums...)
////////////////////////////////////////////////////////////////
// 구조체
//
// 구조체 정의
type Data sturct {
value int
data [200]int
}
// 중첩된 구조체
type User struct {
Name string
}
type VIPUser struct {
User // 타입만 적고, 필드를 안 적었음. 그럼 필드가 풀려서 들어감.
level int
}
vip := VIPUser { User{"화랑"}, 1 }
vip.Name // User에 정의한 Name를 VIPUser에서 바로 사용 가능.
// 만약 VIPUser에도 Name이 있으면, VIPUser.Name으로 접근. User.Name은 VIPUser.User.Name으로 접근
vip := VIPUser { "VIP이름", User{"User이름"}, 1 }
vip.Name // VIP이름
vip.User.Name // User이름
////////////////////////////////////////////////////////////////
// 포인터
//
// 포인터는 이렇게 씀. 구체적인 설명은 생략.. 다들 대충 알잖아? ㅋ
var v int = 500
var p *int // 이 상태일때 p는 nil 상태(사실은 0임)
p = &v
*p = 100
////////////////////////////////
// 구조체의 포인터 사용법
//
// 구조체 정의
type Data sturct {
value int
data [200]int
}
// 레퍼런스를 받는 함수
func dd ( arg *Data ) { // 포인터 주소로 구조체 객체 접근 가능.
arg.value = 1
arg.data[100] = 2
}
func main() {
// 방법 1
var data Data // 구조체 생성
dd ( &data ) // 구조체 객체의 포인터 주소 전달
// 방법 2
var data Data
var p *Data = &data
dd ( p ) // 이미 p가 주소이기 때문에 굳이 다시 &를 붙이 필요가 없음.
// 방법 3
var p *Data = &Data{} // 구조체 생성한 주소를 바로 p 에 할당. 굳이 data 변수 안 만들어도 됨.
var p *Data = &Data{3, 4} // 구조체 생성할때 필드 초기값을 주고 생성할 수도 있음.
dd ( p )
// 방법 4
var p = new(Data) // new만 써도 알아서 타입에 맞는 포인트 변수 생성 가능. 단 필드 초기값은 못 줌.
}
////////////////////////////////
// 일반적으로 구조체를 생성할 때는 객체의 포인터를 반환하는
// newXXX 따위의 생성자 같은 함수를 만들어 쓰더라.
type User struct {
Name string,
Age int
}
func NewUser( name string, age int ) *User {
var u = User{name, age}
return &u
}
userPointer := NewUser("AAA", 123)
////////////////////////////////////////////////////////////////
// 타입 정의. 함수의 타입도 정의 가능.
// 함수가 1급 객체임. 즉, 함수를 변수 할당, 파라미터로 전달, 심지어 return도 가능.
func add(x int, y int) int {
return x + y
}
type OperatorFunc func(int, int) int // 함수의 정의를 OperatorFunc 라는 타입으로 정의
func operate(x int, y int, op OperatorFunc) int { // 파라미터로 OperatorFunc 라는 함수를 받을 수 있음.
return op(x, y)
}
result = operate(3, 4, add) // add 라는 함수가 OperatorFunc 타입이니깐, 파라미터로 전달 가능.
////////////////////////////////////////////////////////////////
// 함수를 동적으로 생성할 수도 있음.
// 하지만 이 때 생성된 함수로 전달되는 변수는 라이프사이클이 완료될때 까지 참조로 유지됨
// 쉽게 말하면 클로저에 대한 설명임.
var funcs []func()
var i = 0
// 함수 리터럴을 생성하고, 변수 i의 참조를 함수로 전달합니다.
// i의 라이프사이클이 끝날때까지 함수 안에서 i는 참조로 활용됩니다.
for i = 0; i < 2; i++ {
funcs = append(funcs, func() {
fmt.Println(i)
})
}
// i의 값을 10으로 바꿉니다.
i = 10
// 동적으로 생성한 함수에서 사용한 i 참조가 아직 죽지 않았으므로
// 함수가 호출 될 때 i의 "최신 상태"를 실시간으로 반영합니다.
// 그러므로 출력은 0 1이 아니라 10 10 이 출력됩니다.
for _, f := range funcs {
f()
}
{
// 동적으로 함수가 생성될 때 v가 사용되나, 이 블럭을 벗어나면 v는 더 이상 살아 있지 않습니다.
// 하지만 함수 실행시 사용되어야 하므로, 이 함수 내에서만 v가 살아 있게 됩니다.
// 이 함수를 여러번 호출하면 내부에 살아 있는 v가 1씩 더해 질 것입니다.
// 이런걸 클로저리고 합니다.
var v = 100
funcs = append(funcs, func() {
fmt.Println(v)
v = v + 1
})
}
// 생성한 함수를 호출합니다.
// 10 10 100 이 출력될 것입니다.
for _, f := range funcs {
f()
}
// 내부에 살아 있는 v가 1씩 더해 질 것이므로
// 101 102 103 이 출력 될 것입니다.
funcs[2]()
funcs[2]()
funcs[2]()- Go가 함수를 호출하면 call by value 다. 그렇지만 &를 이용해서 주소 값을 얻어 낼 수 있으므로, reference를 전달 할 수 있기는하다.
- *(포인터)형 변수는 함수의 파라미터로 전달 될때, &를 붙이지 않아도 알아서 주소값이 전달된다. 대신 함수에서는 &로 받아야만 그 객체에 제대로 접근할 수 있다.
문자열
var c rune = '찬' // rune은 걍 int32임. 걍 c를 출력하면 52268 가 나옴. %c를 써야 '찬'이 나옴
///////////////////
str = "찬찬찬" // Go에서 string은 UTF-8을 기준으로 처리됨.
len(str) // 9. len()은 byte의 크기를 나타냄. 한글 1글자가 UTF-8에서 3byte니깐 9가 출력되는거임.
///////////////////
runes_str := []rune(str) // UTF-8 string을 rune n개로 즉, int32 3개로 변경함.
len(runes_str) // 3. int32 배열 3개니깐, 3이 나옴.
///////////////////
// 재미난건 string type이지만 range 를 사용하면, unicode 1개씩 루프를 돌 수 있다는거임.
// range라는 용어만보면 배열, 슬라이드, map의 loop만 돌것 같지만
// string이나 channel 에서도 "특별한 방식"으로 동작하니깐 알아 둬야함.
str = "안녕함?"
for _, v := range str {
fmt.Printf("%c", v) // 안녕함? 이 출력됨
}
///////////////////
// 문자열 합치기
str1 := "냐냐"
str2 := "냠냠"
str3 := str1 + str2
str1 += " " + str2
///////////////////
// 문자열 비교, ==과 != 으로 비교 가능. > >= <= < 로 Unicode Index로 비교도 가능
str1 == str2
str1 > str2
///////////////////
// string은 사실 구조체임.
type StringHeader struct {
Data uintptr // Data라는 놈은 사실 포인터임.
Len int
}
str1 = "뿅" // str1.Data(unintptr)값이 "뿅"이라는 글자의 주소를 가리킴.
str2 = str1 // str1에 있던 Data 값(주소)과 Len 값을 str2로 복사.
// 즉, str2에 할당될때, 사실은 포인터 값이 복사 되고 있는 거임.
///////////////////
// string의 타입이 변환 될 때는 "복사" 된 뒤 변환됨.
str := "Hello"
slice := []byte(str)
slice[1] = 'Q' // str은 여전히 Hello 이고, slice만 Qello 로 변함.fmt.Printf(...)
fmt.Printf("%d", 12) // 이런식으로 출력할 수 있다.
// %v가 매우 특별한데, "알아서 잘 출력하라" 정도 된다.
fmt.Printf("%T %v", 12, 12) // int 12 // 12라고 적으면 int type이 됨. 주의 필요.
fmt.Printf("%T %v", 19.6, 19.6) // float64 19.6
fmt.Printf("%T %v", '찬', '찬') // int32 52268 // rune은 int32, 즉 숫자니깐 숫자로 출력됨
fmt.Printf("%T %v", "찬", "찬") // string 찬
// 출력가능한 형식 지정자(format specifier) ChatGPT가 알려 준 거 붙여둠. ㅎ.
////////////////////////////////////////////
// bool, int, float
// %t: 불리언 값을 출력합니다.
// %b: 정수를 2진수로 출력합니다.
// %d: 정수를 10진수로 출력합니다.
// %o: 정수를 8진수로 출력합니다.
// %x: 정수를 16진수로 출력합니다(소문자 a-f).
// %X: 정수를 16진수로 출력합니다(대문자 A-F).
// %f: 부동소수점 수를 소수점 아래 6자리까지 출력합니다.
// %F: 부동소수점 수를 소수점 아래 6자리까지 출력합니다(%f와 동일).
/////////////////////////////////////////////
// 문자, 문자열, 배열
// %c: 정수를 해당하는 유니코드 문자로 출력합니다.
// %q: 정수를 해당하는 유니코드 문자로 출력하되, 따옴표로 묶습니다.
// %s: 문자열이나 바이트 슬라이스를 직접 출력합니다.
// %q: 문자열이나 바이트 슬라이스를 따옴표로 묶어서 출력합니다.
// %U: 정수를 유니코드 형식으로 출력합니다.
// %x: 문자열이나 바이트 슬라이스의 각 바이트를 2자리 16진수로 출력합니다(소문자 a-f).
// %X: 문자열이나 바이트 슬라이스의 각 바이트를 2자리 16진수로 출력합니다(대문자 A-F).
/////////////////////////////////////////////
// 타입 별 특별한 것
// %T: 값의 타입을 출력합니다.
// %p: 포인터의 주소를 16진수로 출력합니다.
//
// %v: 값을 "기본 형식"으로 출력합니다. 복합 타입의 경우, 요소들은 재귀적으로 출력됩니다.
// %+v: 구조체의 경우, 필드 이름을 함께 출력합니다.
// %-v: 구조체의 경우, 필드 이름을 함께 출력하되 구조체의 내용만 출력합니다.
// #%v: 값의 Go 구문 표현을 출력합니다. 예를 들어, 문자열은 따옴표로 묶이고, 배열과 슬라이스의 요소는 재귀적으로 출력됩니다.
/////////////////////////////////////////////
// 기타
// %%: 리터럴 퍼센트 문자를 출력합니다(%는 그 자체로 출력됩니다).
/////////////////////////////////////////////
// 잘 사용하지 않는 부동 소숫점
// %b: 부동소수점 수를 과학적 표기법으로 출력합니다(ex: -1234567890.123456789e+10).
// %e: 부동소수점 수를 소문자로 된 과학적 표기법으로 출력합니다(ex: -1.234567e+10).
// %E: 부동소수점 수를 대문자로 된 과학적 표기법으로 출력합니다(ex: -1.234567E+10).
// %g: 부동소수점 수를 더 짧은 Precision으로 출력합니다(%e 또는 %f 중 짧은 쪽).
// %G: 부동소수점 수를 더 짧은 Precision으로 출력합니다(%E 또는 %F 중 짧은 쪽).if, switch, for
////////////////////////////////////////////////////////////////////////////////////
// if의 일반적인 문법
if conditon {
//
} else if condition {
//
} else {
//
}
// if 예제
x := 10
if x > 10 {
fmt.Println("x is greater than 10")
} else if x == 10 {
fmt.Println("x is exactly 10")
} else {
fmt.Println("x is less than 10")
}
//////////////////////////////////////////
// if 사용시 초기화 구문 포함 문법 ( for도 초기화 구문 문법이 있음 )
if statement; condition {
//
}
// if 초기화 구문 예제
if x := 10; x > 5 {
fmt.Println("x is greater than 5")
}
////////////////////////////////////////////////////////////////////////////////////
// switch 문법중 expression이 있는 문법. expression은 string도 가능하다.
switch expression {
case value1:
// expression이 value1이면 여기가 실행됨.
break; // break를 안 써도 되지만, 써도 됨.
case value2, value3:
// expression이 value2거나 value3면 여기가 실행됨.
// !!!! 중요!!!! break가 없어도 이 부분만 실행됨.
case value4:
// expression이 value4이면 여기가 실행됨
// 다만 아래와 같이 fallthrough 라고 적으면 다음 case로 진행됨. 사용하지 말것.
fallthrough
case value5:
// expression이 value5면 여기가 실행됨.
// !!!! 중요!!!! break가 없어도 이 부분만 실행됨.
default:
// 위의 모든 case가 아닐 때 실행됩니다.
}
// 예제 1
str := "hello"
switch str {
case "hello":
fmt.Println("The string is hello")
case "world", "help", "me" :
fmt.Println("The string is world or help or me")
default:
fmt.Println("The string is not hello or world or help or me")
}
//////////////////////////////////////////
// switch 문법중 초기화 구문과 expression이 같이 있는 문법
// 이곳에서 지정된 statment(변수)는 switch 문 내에서만 사용할 수 있음.
switch statement; expression {
case value1:
///
}
// 예
switch age := getAge(); age {
case 10:
///
}
//////////////////////////////////////////
// switch 문법중 expression이 없는 문법
// 사실 expression 영역이 true 라고 박혀 있는것이랑 같다고 볼수 있음.
// case를 순차적으로 검사해 condition이 첫번째로 true인 곳을 실행
switch {
case condition1:
// condition1 이 true면 여기가 실행됨.
// !!!! 중요!!!! break가 없어도 이 부분만 실행됨.
case condition2:
// condition2 이 true면 여기가 실행됨.
// !!!! 중요!!!! 만약 condition1이 true였다면 condition1만 실행되고 여기는 실행 안됨.
// !!!! 중요!!!! break가 없어도 이 부분만 실행됨.
default:
// 위의 모든 case가 아닐 때 실행됩니다.
}
// 예제
x := 3
switch {
case x > 0:
fmt.Println("x is positive")
fallthrough
case x > 2:
fmt.Println("x is greater than 2")
default:
fmt.Println("x is zero or negative")
}
//////////////////////////////////////////
// switch 문법중 초기화 구문만 있는 문법.
// 사실 expression 영역이 true 라고 박혀 있는것이랑 같다고 볼수 있음.
switch statement; {
case value1:
///
}
// 예
switch age := getAge(); {
case age > 10:
///
}
////////////////////////////////////////////////////////////////////////////////////
// for 일반적인 문법
for initialization; condition; post {
// loop body
}
//////////////////////////////////////////
// for 초기만문 없는 문법
i := 0
for ; i < 5 ; i++ {
fmt.Println(i)
}
//////////////////////////////////////////
// for condition만 있는 문법
i := 0
for ; i < 5 ; {
fmt.Println(i)
i++
}
//////////////////////////////////////////
// for condition만 있는 경우 ; 제거 가능
i := 0
for i < 5 {
fmt.Println(i)
i++
}
//////////////////////////////////////////
// for 아무것도 없는 무한루프
for {
// loop body
}
//////////////////////////////////////////
// for 에서 range 사용하는 방법
nums := []int{2, 3, 4}
for i, num := range nums {
fmt.Printf("index %d: %d\n", i, num)
}배열, 슬라이스
//////////////////////////////////////////////////////////////
// 배열
//
// 배열은 "상수" 크기로 만들 수 있음. const로 정의를 해도 됨. var 따위의 변수는 안됨.
// 동적으로 입력 받아서, 배열의 갯수를 만들 수 없음.
// 문법
var arrayName [arraySize]dataType
// 배열 크기 지정
var nums [5]int
// 아이템의 갯수에 맞춰 알아서 맞는 크기의 배열 생성, ...을 써야함.
nums := [...]int{2, 3, 4}
// !!!중요!!!
// []int{2, 3, 4} 처럼 ... 없이 쓰는건 배열 생성이 아니라, 슬라이스 생성임 !!!!
// 배열의 크기를 지정하고, 아이템은 덜 넣을 수도 있음. 많이 넣으면 안됨.
nums := [5]int{1, 2, 3, }
// 배열은 value type임. 그러므로 배열에 배열을 할당하면 복사됨.
arr1 := [5]int{ 1, 2, 3 }
arr2 := arr1
arr2[0] = 9 // arr1 : 12300, arr2 : 92300
// 배열에 배열을 할당하면 복사 되어야 하므로, 배열의 크기가 서로 다르면 할당이 될 수 없음
arr1 := [5]int{1, 2, 3}
arr2 := [10]int{1, 2}
arr2 = arr1 // 배열 크기가 달라 컴파일 에러 발생. 배열의 크기가 작고, 크고의 문제가 아님.
//////////////////////////////////////////////////////////////
// 슬라이스
// 배열과 달리 고정이 아님. ArrayList 같은거임. 근데 이게 len이랑 cap 이라는게 있어 짜증남.
// 즉, 제대로 이해하지 못하면 무슨일이 생기는지 알 수 없으니 찬찬히 읽어 볼 것.
//
// 슬라이스 생성방법
s := make([]int, 3, 5) // 길이가 3이고 용량이 5인 슬라이스 생성
s := []int{7,8,6} // 길이가 3이고 용량이 3인 슬라이스 생성
///////////////////////////
s1 := make([]int, 3, 5) // 길이가 3이고 용량이 5인 슬라이스 생성
s2 := append(s1, 10, 11) // s1에 아직 2개의 빈칸이 있고 거기에 10과 11을 넣고 s2가 그걸 가리킴
// s2는 길이가 5 용량도 5. 아직은 같은 데이터를 바라 보고 있음.
s1[0] = 99 // s1과 s2가 같은 데이터를 보고 있으므로, s1[0] 에 99를 넣으면, s2[0]도 99로 변함.
// 다만 s1은 len이 3이므로 99, 0, 0 만 봄
// 반면 s2의 len은 5이므로 99, 0, 0, 10, 11을 볼 수 있음
//// 여기서 중요!!!
s3 := append(s2, 12) // s2의 길이가 5이고 용량이 5이니, 12를 넣을 수 없는 상황임.
// 그러므로 s2의 데이터를 새 공간으로 복사하고 거기에 12를 추가. s3가 새 공간을 보게 됨.
// s3의 len은 6이 되고, cap은 10이 됨 ( 새 슬라이스가 생성될때 cap이 적절히 늘어날 꺼임 )
s3[1] = 55 // s3는 새공간이므로 s3[1]에 55를 넣는다고 해도, s1[1], s2[1]에는 영향 없음
// s1 = 99 0 0 , s2 = 99 0 0 10 11 , s3 = 99 55 0 0 10 11 12
///////////////////////////////////////
// 슬라이스의 일부를 새로 포인팅할 수 있는 슬라이스 만들기
s1 := []int{7, 8, 6, 5, 2} // 길이가 5이고 용량이 5인 슬라이스 생성
ns = s1[2:4] // s1의 index 2에서 4전까지(즉, index 2, 3)로 슬라이드(포인팅) 생성. ns는 5 6 임.
ns[1] = 99 // ns는 s1을 포인팅하고 있으므로, ns[1]도 99가 되고, s1[3]도 99가 된다.
///////////////////////////////////////
// 슬라이스의 상태가 관리가 어려우니깐 걍 복사해서 쓰면 편하겠지?
// append와 ... 으로 풀어줘서 복사.
s2 := append([]int{}, s1...)
// copy로 복사
s_5_5 := []int{ 1, 2, 3, 4, 5 }
s_3_7 := make([]int, 3, 7)
s_7_7 := make([]int, 7, 7)
s3count := copy( s_3_7, s_5_5 ) // s_3_7이 1, 2, 3 으로 채워짐, return 복사된 갯수 3
s7count := copy( s_7_7, s_5_5 ) // s_7_7이 1, 2, 3, 4, 5, 0, 0 으로 채워짐. return 복사된 갯수 5덕타이핑, 메소드, 인터페이스
- 이 글을 읽는 사람이 프로그래밍을 어느정도 알고 읽는다는 가정하에 정리 중이다.
- Golang은 클래스의 상속관계가 없다. 하지만 interface Type으로 메소드를 호출할 수 있는 방법이 있다. 덕 타이핑이라는 방법이다. 덕 타이핑은 옛날 영국시인이 말했던 "만약 어떤 새가 오리처럼 걷고, 오리처럼 꽥꽥거리면 그것은 오리다." 라는 개념이다.
- 명시적인 상속관계로 부모 interface를 구현하는게 아니라, 그냥 부모 interface의 메소드를 구현하면, 부모 interface로 호출할 수 있다.
- 예를 만들어 보자.
- Closeable 라는 인터페이스에 Close() 라는 메소드가 정의되어 있다.
- Door라는 struct가(Door Type의 리시버) 호출 할 수 있도록 Close() 메소드를 구현했다. - func ( d Door ) Close() { ... }
- Window라는 struct가(Window Type의 리시버) 호출 할 수 있도록 Close() 메소드를 구현했다. - func ( w Window ) Close() { ... }
- 이제 Door struct나 Window struct를 Closeable 변수에 할당 할 수 있고, 부모 Type의 변수를 이용해 Close() 를 호출 할 수있다.
- 이렇게 되면 "정보를 나타내는 구조체"와 그에 어울리는 "메소드"를 나눠서 별개로 구현할 수 있다.
- Golang의 덕타이핑 방법과, Java의 상속 관계를 이용한 메소드 구현 방법의 차이점을 보자.
- Java : Field만 있는 class를 만들때 final class로 만들어 버리면, 상속 받을 수 없기 때문에, 메소드 구현 불가.
- Golang
- Field만 있는 struct는 그냥 두고, struct에 맞는 메소드를 "별개"로 구현 가능함.
- 그렇기 때문에 Field만 있는 struct를 내가 수정할 수 없는 상황이 되어도, 메소드를 구현 가능함.
- 심지어 내가 필요한 인터페이스와, 내가 필요한 메소드를 상속관계를 고민하지 않고 추가 가능.
- 인터페이스, 메소드, 덕타이핑에 관련 예제는 아래를 참고하자. ( ChatGPT 에게 만들어 달라고 했음. ㅋ )
type Closeable interface {
Close()
}
type Door struct {
IsOpen bool
}
func (d *Door) Close() {
d.IsOpen = false
}
type Window struct {
IsOpen bool
}
func (w Window) Close() {
w.IsOpen = false
}
func CloseAll(items []Closeable) {
for _, item := range items {
item.Close() // 포인터타입 &Door와 값타입 Window를 *나 &를 사용하지 않고 호출하네??
}
}
func main() {
door := &Door{IsOpen: true}
window := Window{IsOpen: true}
CloseAll([]Closeable{door, window})
}- 위 예제에서 아주 중요한 것에 대해 설명하지 않았다. 코드의 마지막 main 함수를 보면 있는 door는 &, 즉 포인터형 변수이고, window는 값형 변수이다. 실제 메소드의 정의를 봐도 알겠지만 Door는 포인터형 리시버인 (d *Door) 를 사용하고 있고, Window는 값형 리시버인 (w Window) 를 사용하고 있다.
- 하지만, 각 메소드의 실제 구현 코드를 확인해 보면, 값타입과 포인터 타입을 적절히 구분하기 위해서 * 나 & 를 사용해 코드를 짜지 않고, 걍 d 나 w를 바로 사용하고 있다.이건 Golang 이 알아서 적절히 *나 &가 붙은것 처럼 동작 시켜줘서 가능한거다. 그러니 걱정하지 말자.
인터페이스 좀 더 정리
///////////////////////////////////////////////////////////////////
// Reader, Writer, Closer 인터페이스를 만들고 이걸 모아둔 File 인터페이스 만들기
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
// 아래 코드는 마치 Java에서 interface File extends Reader, Writer, Closer 한것과 같이 동작한다.
type File interface {
Reader
Writer
Closer
Get() string // 이렇게 File만을 위한것도 따로 추가 가능.
Close() error // Closer 인터페이스 메소드와 시그니처가 같으므로 합쳐짐. 시그니처가 다르면 에러남.
}
///////////////////////////////////////////////////////////////////
// 구조체 정의, 이 Type을 리시버로 하는 Get, Read, Write, Close 메소드를 구현할 꺼임
type MyFile struct {
name string
}
///////////////////////////////////////////////////////////////////
// File 인터페이스를 구현하면 Reader, Writer, Closer 인터페이스를 모두 구현하게 될거다.
func (f *MyFile) Get() string {
return f.name
}
func (f *MyFile) Read(p []byte) (n int, err error) {
fmt.Printf("%s is reading\n", f.name)
return 0, nil
}
func (f *MyFile) Write(p []byte) (n int, err error) {
fmt.Printf("%s is writing\n", f.name)
return 0, nil
}
func (f *MyFile) Close() error {
fmt.Printf("%s is closed\n", f.name)
return nil
}
func main() {
f := &MyFile{"MyFile"}
// MyFile 인스턴스는 File, Reader, Writer, Closer 인터페이스를 만족하므로
// 이 인터페이스들의 메서드들을 직접 호출할 수 있습니다.
var fi File = f
var r Reader = f
var w Writer = f
var c Closer = f
fmt.Printf("Processing %s...\n", fi.Get())
r.Read(nil)
w.Write(nil)
c.Close()
}defer, error, panic, recover
//////////////////////////////////////////////////////////////
// defer - 함수나 메소드를 벗어 나기 전에 실행됨. 예외나 에러가 발생해도 defer는 실행됨
// "미리" 적어둬도 알아서 실행되니 stream 따위를 open 한 다음줄에 적어 두면 좋음.
//
// 아래에 예제는 1 3 2 순으로 출력된다. defer는 메소드를 벗어날때 실행되기 때문이다.
func main() {
fmt.Println("1")
defer fmt.Println("2")
fmt.Println("3")
}
// 만약 함수나 메소드에 여러개의 defer가 있으면, 마지막에 있는 defer 부터 실행됨
// 아래 예제는 2가 출력되고, 1이 출력된다.
func main() {
defer fmt.Println("1 defer")
defer fmt.Println("2 defer")
}
// 주로 사용할 만한 예제는 파일을 열고 닫을때 사용하는 defer 일꺼다.
func main() {
file, err := os.Open("test.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close() // 까 먹지 않게, 열자 마자 나중에 닫을꺼라고 적어 두자.
bytes, err := ioutil.ReadAll(file)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(bytes))
}
//////////////////////////////////////////////////////////////
// error - 함수 실행후 제대로 실행되지 않았음을 표시한다.
// errors.New 에러를 생성하거나 fmt.Errorf 를 이용해서 생성할 수 있음.
// 주로 리턴하는 할때 제일 마지막에 error 를 포함시킨다.
// MySqrt 함수는 제곱근을 계산합니다. 입력 값이 음수라면 에러를 반환합니다.
func MySqrt(x float64) (float64, error) {
if x < 0 {
return 0, errors.New("can't take square root of negative number")
// fmt.Errorf("can't take square root of negative number") 로 생성해도 됨.
}
return x, nil
}
func main() {
_, err := MySqrt(-1)
if err != nil {
fmt.Println("Error:", err)
}
}
// error의 인터페이스인 Error() string만 구현하면 사용자 정의 에러도 만들 수 있다.
type MyError struct {
Msg string
Code int
}
func (e MyError) Error() string {
return fmt.Sprintf("MyError: %s, Code: %d", e.Msg, e.Code)
}
func doSomething() error {
// 에러 발생 시 사용자 정의 에러를 반환
return MyError{"Something went wrong", 123}
}
err := doSomething()
if err != nil {
switch e := err.(type) { // 에러의 타입을 확인해서, 내가 정의한 에러면 따로 처리 가능.
case MyError:
fmt.Println("Handling MyError:", e.Msg, e.Code)
default:
fmt.Println("Unknown error:", err)
}
}
//////////////////////////////////////////////////////////////
// panic : 실행도중 문제가 생기면, interface{} 타입, 즉 모든 type의 정보를 throw 시킬 수 있다.
// recover : throw된 panic을 잡아서, panic이 보내준 정보를 받아 이런저런 처리를 할 수 있다.
//
// panic이 발생하면 함수를 벗어날꺼고, 그럼 defer가 실행될거다.
// defer를 이용해 recover를 실행할 수 있도록 해 두면, panic이 던진 문제를 적절히 잡아서 해결 할 수 있다.
func main() {
// defer로 함수를 하나 동적으로 생성해 지정해 주자.
defer func() {
// 만약 painc이 발생했다면, recover()의 return 값이 있을꺼다. 그걸 보고 예외처리를 하자.
if r := recover(); r != nil {
switch t := r.(type) {
case string:
fmt.Println("String panic:", t)
case func() int: // 심지어 painc이 return type이 있는 function도 던질 수 있음.
i := r.(func() int)() // 요런식으로, 타입 변환 후에 실행할 수도 있다.
fmt.Println(i)
fmt.Println("Function panic:", t)
case PanicInfo:
fmt.Println("PanicInfo panic:", t.Location, t.Problem)
default:
fmt.Println("Unknown panic:", t)
}
}
}()
// Panic with a string
panic("A string panic")
// Panic with a function
panic(func() int { fmt.Println("An anonymous function"); return 1 })
// Panic with a struct
panic(PanicInfo{"main", "A struct panic"})
}지금부터는 개념 설명이 많이 필요한 부분이라, 걍 대충 정리해야 겠다. 시간이 너무 오래 걸리네. ㅋ.
고루틴, 뮤텍스
- 자바에서는 동시에 무언가를 실행 시키려고 하면 Thread라는것을 만들어야 한다. 이 때 생성되는 Thread는 무겁다. 그냥 무겁다고 생각하자. 그런데 고루틴은 1개의 Thread에 n개의 작업이 병렬로 실행될 수 있다. 라고 썼는데.. 친절하지 않은것 같아 ChatGPT에게 물어 본거를 간단히 몇개만 써 둔다.
- Java 쓰레드는 JVM에 의해서 관리. 하지만 OS 의존적이다. ( 그래서 Windows랑 Linux 랑 다를 수 있음 )
- Java는 한개의 Thead가 OS에서 관리하는 1개의 쓰레드다. 하지만 고루틴은 직접 스케줄링해서 1개의 OS thread에 n개의 고루틴이 들어 갈 수 있다. 즉, CPU 단에서 발생하는 스레드 스위칭이 적을 수 밖에.
- Java는 한개의 Thread를 만들때 512KB ~ 1MB의 stack을 생성하나, 고루틴은 2~8KB 만 생성.
- 그래서 고루틴은 하나의 프로세스에서 수천, 수백만개의 고루틴도 실행 될 수 있다.
- 참고로 Java도 19부터 Virtual Thread라는게 Preview로 들어 왔는데, 요 놈은 가볍다고 한다.
- 각설하고 예제나 보자.
///////////////////////////////////////////////////////
// gorutine은 병렬로 실행될 함수명을 적으면 끝이다.
func printNumber() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("Number: %d\n", i)
}
}
func printLetters() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("Letter: %c\n", i)
}
}
func main() {
go printNumber() // 숫자 출력을 병렬로 실행
go printLetters() // 글자 출력을 병렬로 실행, 두 함수의 sleep시간 차이로 적절히 섞여서 출력된다.
// 고루틴은 끝나지 않았지만, main 함수를 실행시키는 gorutine이 끝나면 프로세스가 종료된다.
// 위 두개의 go rutine이 끝날때까지 main이 종료되지 않도록 하자.
time.Sleep(3 * time.Second)
// main 함수도 gorutine이라면, 왜 얘는 끝날때까지 기다리냐고? 그냥 그렇게 만들어 뒀기 때문이다. ㅎ.
}
///////////////////////////////////////////////////////
// gorutine이 끝날때까지 Sleep 하는건 말도 안되는 짓이니 sync.WaitGroup으로 좀 더 똑똑하게 해 보자.
// Java에 있는 CountDownLatch 같은거라고 생각하면 편하다.
//
func worker(id int, wg *sync.WaitGroup) {
// 함수를 벗어날때 waitGroup의 count에서 1개를 빼 준다.
defer wg.Done()
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
// waitGroup을 만들어 기다릴 수 있는 기능을 쓰자.
// waitGroup에 카운트를 더했다(Add) 뺐다(Done) 하자.
// wg.Wait()로 기다릴 수 있고, count가 0 이 되면 모든 작업이 끝났으니 다음으로 진행된다.
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1) // waitGroup 에서 count 해야할 갯수를 추가한다.
go worker(i, &wg) // wg를 포인터로 넘겨야 한다. 그래야 고루틴마다 "상태 공유"를 할 수 있다.
}
// waitGroup 만들어 둔게, Done 될 때까지 여기서 대기한다.
wg.Wait()
}
///////////////////////////////////////////////////////
// Mutex 로 동시성 문제 해결하기. 동시성 문제에 대해서는 굳이 설명 안함.
// Mutex로 Lock을 잡고, 처리 한 뒤에 Unlock() 수행하면 됨. 끝.
//
var x = 0
func increment(wg *sync.WaitGroup, m *sync.Mutex) {
m.Lock()
defer m.Unlock() // 세상에! 여기다 defer를 쓰면, Unlock을 하지 않는 실수를 줄일수 있다.
x = x + 1
wg.Done()
}
func main() {
var w sync.WaitGroup
var m sync.Mutex
for i := 0; i < 1000; i++ {
w.Add(1)
go increment(&w, &m)
}
w.Wait()
fmt.Println("final value of x", x)
}채널, 컨텍스트
- 고 언어에서는 채널이 매우 중요한 개념이다. 하지만 설명하기 귀찮으므로, 예제만 고고싱.
////////////////////////////////////////////////////////////////////
// 채널은 특정 Type이 들어 갈 수 있는 BlockingQueue라고 생각하면 편하다.
// 채널은 아래와 같은 형식으로 생성한다.
ichannel := make(chan int)
// 채널이 몇개의 buffer를 가질지도 정할 수 있다.
// buffer만큼까지는 바로 집어 넣을 수 있고,
// buffer가 가득차면 넣는애도 buffer가 빌때까지 "대기"해야 한다.
ch := make(chan int, 2) // 두개의 buffer를 가진다.
ch <- 1 // 첫번째꺼 넣고
ch <- 2 // 두번째꺼 넣어 buffer가 가득 찼음.
ch <- 3 // 원래라면 이미 buffer가 가득 찼으므로 대기해야함.
// 근데 go는 똑똑하게 buffer를 비워줄 애가 없다는것을 알고 있어서, deadlock 이 생겼다면서 죽음.
// 채널을 닫으려면 아래와 같이 close를 사용하면 된다.
close(ichannel)
////////////////////////////////////////////////////////////////////
// 채널과 go루틴을 활용하는 간단한 예제
// string들이 보관될 수 있는 채널(Queue) 생성
messageChan := make(chan string)
// 함수를 하나 go루틴으로 실행한다.
// string이 보관될 채널에 "Hello, Channel!" 을 넣는다.
go func() {
messageChan <- "Hello, Channel!"
}()
// string이 보관된 채널에서 값을 읽는다.
// 위 함수가 실행되지 않았다면 messageChan 에 아무런 값이 없을 것이므로, "대기" 한다.
// 위 함수가 실행되면 messageChan에 "Hello, Channel!" 가 있을 것이므로, 꺼내온다.
message := <-messageChan
fmt.Println(message) // "Hello, Channel!" 출력
////////////////////////////////////////////////////////////////////
// 채널에서 데이터가 올때마다 처리하기.. ragne 사용
func produce(c chan<- int) {
for i := 0; i < 10; i++ {
time.Sleep(100 * time.Millisecond) // sleep for 100 milliseconds
c <- i
}
close(c)
}
func main() {
c := make(chan int)
// c 채널에 일정시간마다 값을 추가하는 채널 고루틴 실행.
go produce(c)
// 아래와 같이 하면 채널에 값이 채워 질 때마다 v 에 값을 할당하고 실행된다.
// c 채널이 close 될때까지 실행된다.
for v := range c {
fmt.Println(v)
}
}
////////////////////////////////////////////////////////////////////
// 채널이 2개 이상이라면, 하나의 채널에서 데이터가 올때까지 기다리고 있으면
// 나머지 채널에서 데이터가 도착했더라도, 받을 수 없는 문제가 있다.
// 이 때는 select를 사용하면, 각 채널 별로 오는 데이터를 동시에 기다릴 수 있다
// 동시에 기다릴 수 있는거지, 동시에 처리할 수 있는것은 아니다.
// 만약 동시에 처리하고 싶다면, select case에서 또 go 루틴을 만들면 될 거다.
func sender(ch chan<- string, msg string, waitTime time.Duration) {
time.Sleep(waitTime)
ch <- msg
}
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
go sender(ch1, "Message from channel 1", 2*time.Second)
go sender(ch2, "Message from channel 2", 1*time.Second)
for i := 0; i < 2; i++ {
select {
case msg1 := <-ch1:
fmt.Println(msg1)
case msg2 := <-ch2:
fmt.Println(msg2)
}
}
}
////////////////////////////////////////////////////////////////////
// 채널과 select, tick을 사용해서 일정 시간마다 뭔가 실행하게 하기
// time.Tick이나 time.After는 정해진 시간에 채널을 생성해 줌.
// 단, time.Tick는 종료 방법이 없으므로 주의해서 사용해야 함.
// Ticker는 조정이 가능하므로, 상황에 맞춰서 쓰자.
func main() {
ticker := time.NewTicker(500 * time.Millisecond)
defer ticker.Stop()
done := time.After(5 * time.Second) // 5초후에 이벤트를 발생시킬 채널 생성.
for {
select {
// done이라는 채널에서 값이 오면 처리 됨.
// 아래 코드에서는 현재 시간을 안 받았는데 case t := <-done 을 쓰면 현재 시간 알 수 있음.
case <-done:
fmt.Println("Done!")
return
case t := <-ticker.C: // ticker.C 에 현재 시간이 들어 있음.
fmt.Println("Current time: ", t)
}
}
}
////////////////////////////////////////////////////////////////////
// 컨텍스트 : 동시성을 제어해 줌.
// 쉽게 말하면 고루틴에 정보를 전달하거나, 작업을 취소하거나, Timeout 등이 가능함.
func main() {
// 1초후에 ctx.Done 채널에 값을 넣어 주는 컨텍스트 생성
// 파리미터의 context.Background() 는 부모 ctx 다.
// 지금 생성한 ctx를 다음 context 생성할 때 넣어 주면, 추가적으로 적용된다. 아래에 예제 있음.
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
ch := make(chan int)
// 2초 후에 ch 채널에 숫자 1 추가하는 고 루틴 실행.
go func() {
time.Sleep(2 * time.Second)
ch <- 1
}()
// ctx.Done() 이 반환하는 채널에는 1초후에 데이터가 채워질거고,
// ch 채널에는 2초후에 숫자 1 데이터가 채워질 것이므로,
// 결과저으로는 ctx.Done() 부분이 실행되면서 Timeout 이 출력됨.
select {
case <-ctx.Done():
fmt.Println("Timeout")
case <-ch:
fmt.Println("Success")
}
}
// 이런 컨텍스트는 아래와 같은게 있음
// context.WithDeadline : 언제가 되면 Done() 채널에 값 추가.
// context.WithTimeout : 얼마가 지나면 Done() 채널에 값 추가. WithDeadline(parent, time.Now().Add(timeout)) 과 동일함.
// context.WithCancel : cancel 함수를 호출하면 Done() 채널에 값 추가.
// context.WithValue : context에 map 따위로 데이터 추가. 걍 고루틴이 실행되는 함수의 파라미터로 해도 될것 같지만, 이게 표준이래...
///////////////////////////////////////////////////////////
// context.WithCancel 예제
func operation(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("Operation stopped.")
return
default:
fmt.Println("Operation in progress...")
time.Sleep(1 * time.Second)
}
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
go operation(ctx)
time.Sleep(5 * time.Second)
fmt.Println("About to cancel operation...")
cancel()
time.Sleep(1 * time.Second)
}
///////////////////////////////////////////////////////////
// context.WithValue 예제
func doWork(ctx context.Context) {
// Check if userID exists in context
if v := ctx.Value("userID"); v != nil {
fmt.Printf("Doing work for user %s\n", v.(string))
// Simulate work
time.Sleep(time.Second)
} else {
fmt.Println("userID not found in context")
}
}
func main() {
// 아래와 같이 하면 n개의 key vlaue를 추가 가능함.
ctx := context.WithValue(context.Background(), "userID", "user123")
ctx = context.WithValue(ctx, "userName", "Chan")
// Do work for specific user
go doWork(ctx)
// Wait for work to finish
time.Sleep(2 * time.Second)
}
///////////////////////////////////////////////////////////
// 여러개의 context를 하나로 만들어서 전달하고 싶은 경우 아래와 같이 할 수 있음
ctx := context.Background()
ctx = context.WithValue(ctx, "key1", "value1")
ctx = context.WithValue(ctx, "key2", "value2")
// Set a timeout for the context
ctx, cancel := context.WithTimeout(ctx, time.Second*10)
defer cancel()
// The context will now have both the key-value pairs and the timeout모듈, 패키지
모듈, 패키지 부분은 당연히 책에서는 설명 되어 있으나, 나는 여러번 읽었으나 잘 이해하기가 어려웠다. 특히 이전에 사용하던 GOPATH 와 모듈의 도입, 그리고 github에 있는 모듈을 로컬로 연결해 주기 위해서 이런저런것을 한다는것 자체가 잘 이해가 안 됐다. 머리가 말랑말랑하지 못한가 보다. ㅎ.
ChatGPT에게 모듈과 패키지에 대해서 물어 봤고, 그 중에서 정리할 만한것만 대충 적어 둔다. 그런데 ChatGPT 가 예전 정보만 알고 있어서, 지금 이렇게 정리 되는글이 맞는지 모르겠다. 따로 확인하지 않았으니 그렇게 알자. 그리고 이 글만 3일째 적고 있어서 ;; 이제 그만 적을려고...
Go 모듈
- Go 1.11 부터 적용됨, 그 전에는 GOPATH 따위를 사용했음.
- Go 코드들의 묶음. 각 모듈은 하나 이상의 패키지로 구성. 특정 디렉토리에 위치함. 경로가 모듈이름 결정.
- go mod init MODULE_NAME 을 통해서 모듈 생성 가능.일반적으로 github 경로를 사용
- go mod init github.com/yourusername/yourproject
- go get github.com/yourusername/yourproject@v1.2, @latest 따위로 모듈을 다운로드 받음.
- 다만, github.com/yourusername/yourproject 에 소스코드가 반드시 있어야 하는것은 아님
- 해당 경로의 HTML에 <meta name="go-import" content="import-prefix vcs repo-root"> 확인하기도 함.
- go mod tidy : 로컬에 다운로드 받았지만 코드에서 사용하지 않는 모듈들을 제거할 수 있음.
- go mod vendor : 온라인에 있는 모듈은 전부 local /vender 디렉토리에 다운로드 받음. 빌드 할 때도 go build -mod=vendor 를 사용해 로컬에 다운로드 받은 모듈로 빌드 할 수 있음.
패키지
이건 코드와 같이 보는게 좋으니, ChatGPT 내용을 걍 이미지로 복붙한다. ㅎ.

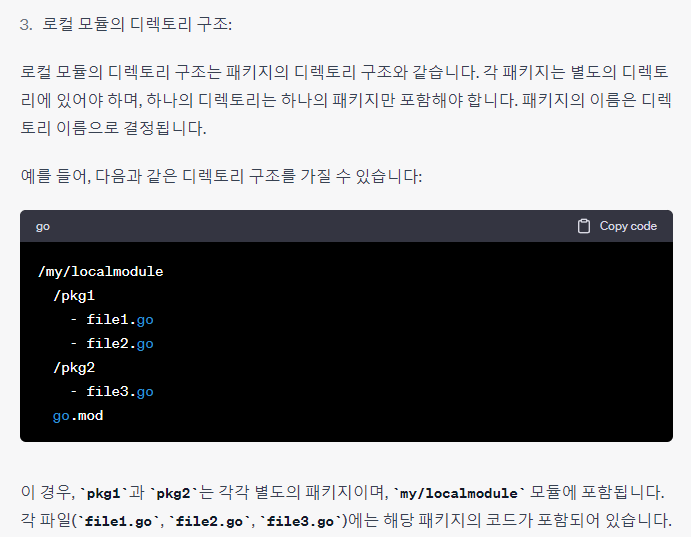
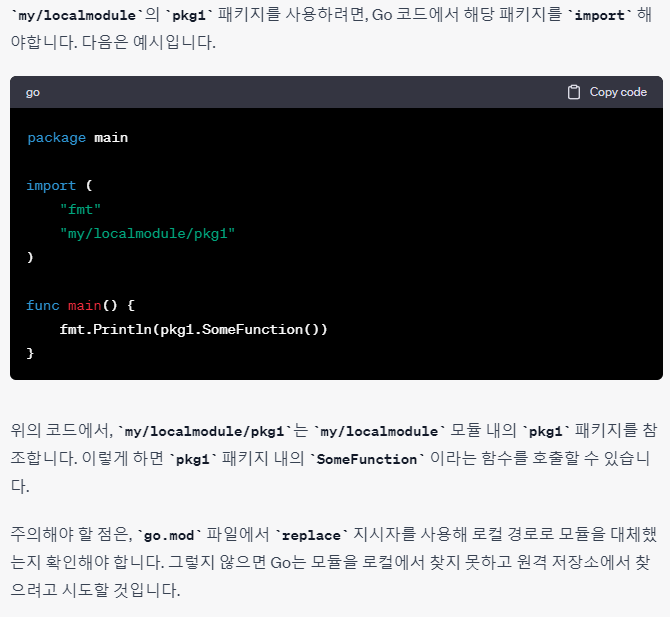

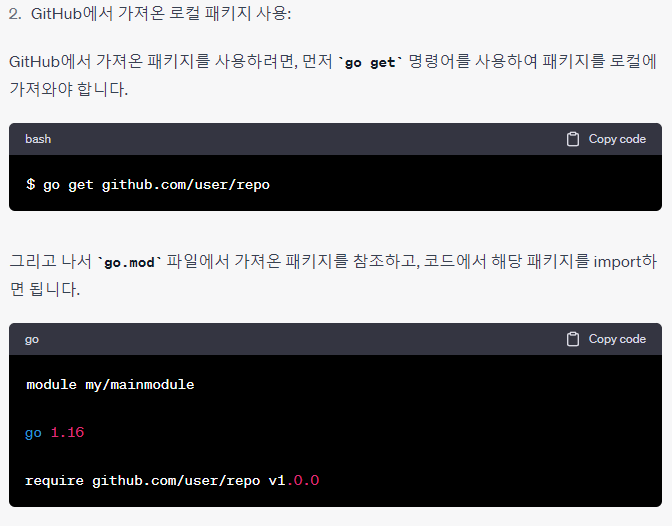

반응형



